GOLANG
引言
云原生体系下,golang一定是必须要掌握的高级语言,golang内置的goroutine契合分布式架构的设计,越来越多的关于云的开源项目采用go进行实现。本文参考:http://c.biancheng.net/golang/intro/ ,本文对go的基础知识进行了大致介绍,可参照右侧的大纲检索,本文会持续更新。
这里笔者也推荐一些go练手项目:
- https://geektutu.com/post/gee.html 极客兔兔的7天用go从零实现系列(必须强烈推荐👍,一天天打下来能对很多go的开源项目有个大致的认识,也能学到很多技巧)
- https://courses.calhoun.io/courses 需要挂梯子,作为一些对于go不同的包的练手项目不错
常用命令
go install [package-name]
编译并安装包,如果不是main包则会安装到pkg底下作为库包,如果是main包则会安装到bin底下作为可执行文件
go doc [package] [func]
go手册
go build [file or package]
如果是main包,生成可执行文件(可执行文件名同文件夹名),如果不是main包,不生成可执行文件,只进行编译
如果是单个.go文件,main包中只能对含main函数的go文件进行编译并生成可执行文件,其他包只进行编译
go module
以后默认用go module的方式进行包管理和添加依赖,以后workspace不必在GOPATH下,GOPATH就存放下载的包和编译好的课执行文件
root workspace底下有两个文件,一个是go.mod(包管理),一个是go.sum(包校验),真正的包下载好放在$GOPATH/pkg/mod底下
在root workspace底下用go mod init[模块名]生成go.mod,模块名命名格式为example.com/xxx..(一般就github.com/foo这样),然后引用workspace底下子目录的go文件,用模块名/子目录名的格式引用
==给项目添加依赖(写进 go.mod)的两种方法==:
- 你只要在项目中有 import,然后 go build 就会 go module 就会自动下载并添加(perfect way)
- 自己手工使用 go get 下载安装后,会自动写入 go.mod
常用命令
go mod init
初始化module
go mod tidy
下载缺少的包,清除没有用上的包
go list
-m all列出所有模块
-u -m all列出所有模块及其可能拥有的更新
go get -u [module] 更新模块及其依赖到最新版本
变量命名方式
简短变量声明被广泛用于大部分的局部变量的声明和初始化。var 形式的声明语句往往是用于需要显式指定变量类型地方,或者因为变量稍后会被重新赋值而初始值无关紧要的地方。
- 一般以
变量名:=变量值的形式由编译器自行判断类型并赋值(适用于局部变量,用在初始化的时候,注意是**:=而不是=,左部变量必须未定义,否则会产生编译错误**),==局部变量不可重复声明,声明的变量没有使用也会编译错误(import包如果没有用到也会报错,与java给个警告不同==全局变量可以声明但不使用,或以var 变量名 type = 变量值(var 变量名 = 变量值,自动识别)的形式赋值(适用于全局变量,用在暂时不需要初始化只需要声明的时候,go也会给未进行初始化的变量赋值)。 - 在同一行同时赋值,编译器会根据顺序将右边的值依次赋予给左边的变量,e.g:
a,b,c := 1,2,“hello”,也适用于一个函数有多个返回值时
交换值a,b=b,a
匿名变量的特点是一个下画线“_”,本身就是一个特殊的标识符,被称为空白标识符。它可以像其他标识符那样用于变量的声明或赋值(任何类型都可以赋值给它),但任何赋给这个标识符的值都将被抛弃,因此这些值不能在后续的代码中使用,也不可以使用这个标识符作为变量对其它变量进行赋值或运算。e.g:
a, _ := GetData()当函数有多个返回值但是暂时不需要赋给这么多变量时,用“_“吞掉返回的值go中使用==或者!=等进行比较时,两边的变量类型必须相同,不相同必须进行强制类型转换(注意bool无法与其他类型强转)
双引号声明字符串字面量不能跨行,需要用反引号`,多行字符串一般用于内嵌源码和内嵌数据等(换行会被保留,但是无法用转义)
rune类型代表一个utf-8字符,它同等于int32,byte可表示一个ASCII字符,它同等于uint8
类型转换:go没有隐式转换,需要声明类型转换,valueOfTypeB = typeB(valueOfTypeA)
iota(多用于枚举,多常量声明形式,如以下代码,每显式声明一个const(或组) ,iota都会初始化为0,const组中每增加一行,iota就加1(常用于信号量/标识):
const ( Sunday = iota (Sunday=0) Monday (如果const中没有显式赋值,则赋值为前一行的值,即iota) Tuesday Wednesday Thursday Friday Saturday )类型别名:type TypeAlias = Type (TypeAlias仍然是Type型,只不过取了别名)
类型定义: type TypeAlias Type (没有等号,相当于C语言中的typedef,TypeAlias是一个新类型了,常用于结构体定义)
类型断言:因为接口变量的动态类型是变化的,有时我们需要知道一个接口变量的动态类型究竟是什么,这就需要使用类型断言,断言就是对接口变量的类型进行检查,其语法结构如下:(可以用于interface{}类型变量转换为其他类型变量),==具体参考反射章节==
value, ok := x.(T) x表示要断言的接口变量; T表示要断言的目标类型; value表示断言成功之后目标类型变量; ok表示断言的结果,是一个bool型变量,true表示断言成功,false表示失败,如果失败value的值为nil。指针不能进行偏移和运算(==安全==)
函数变量:类型为func([参数类型] [,参数类型……])[返回类型]
(一般会给函数变量的类型定义一个其他类型,方便标识)
函数变量常常用于搭配匿名函数接收回调函数,使用了回调函数,可以增加灵活性(具体函数由调用主体实现,被调用者只用函数变量来接收参数)
e.g:
// 遍历切片的每个元素, 通过给定函数进行元素访问 func visit(list []int, f func(int)) { for _, v := range list { f(v) } } func main() { // 使用匿名函数打印切片内容 visit([]int{1, 2, 3, 4}, func(v int) { fmt.Println(v) }) }interface{}空接口类型能够接受任意类型变量,==因为interface{}不包含任何函数,所以任何类型都实现了空接口==,interface的底层实际上是eface结构体,==具体参考反射章节中的引用==
type eface struct{ _type *_type data unsafe.Pointer }
项目目录说明
src:用于以包(package)的形式组织并存放 Go 源文件,这里的包与 src 下的每个子目录是一一对应。例如,若一个源文件被声明属于 log 包,那么它就应当保存在 src/log 目录中。
- 同一个目录下所有的go文件只能有一个包名(package相同),但是包名可以与目录名不同(最好是建议相同)
- main 包是Go语言程序的入口包,main函数是入口函数,只有package main的go文件能包含main函数(有且仅有一个),一个Go语言程序必须有且仅有一个 main 包。如果一个程序没有 main 包,那么编译时将会出错,无法生成可执行文件
- ==使用大小写来决定常量,变量,函数等是否可以被外部包所使用,首字母大写就相当于public,首字母小写就相当于private==
条件,循环语句
if 语句使用 tips
(1) 不需使用括号将条件包含起来
(2) 大括号{}必须存在,即使只有一行语句
(3) 左括号必须在if或else的同一行,if的右括号要与else同一行(或者有多个else if的话)
(4) 在if之后,条件语句之前,可以添加变量初始化语句,使用;进行分隔(==常用于接收条件==)
(5) 在有返回值的函数中,最终的return不能在条件语句中
for
(1) 不需要使用括号
(2) 没有while语句,for condition {}相当于while,for{}相当于while(1)
switch
var a = "hello"
switch a {
case "hello","cello":
fmt.Println(1)
case "world":
fmt.Println(2)
default:
fmt.Println(0)
}
(1)case与case是独立的代码块,不需要break
(2)case的判断可以是表达式也可以多值,如上所示
type-switch
用来判断接口变量的类型,有点Scala的感觉
switch 接口变量.(type) {
case 类型1:
// 变量是类型1时的处理
case 类型2:
// 变量是类型2时的处理
…
default:
// 变量不是所有case中列举的类型时的处理
}
是某个case的类型就匹配,否则匹配default
select
结构类似switch,但是如果有多个同时case匹配,switch是顺序执行,==select是随机执行==,只能用于通道的读写
- select循环一旦某个case匹配只会执行一次,可以通过在for{}循环中嵌套select来不断地监听通道,但是select中某个case使用break只会退出当前select的执行,并不会退出外层for{}循环
- 一般使用非阻塞收发,即存在default,否则select会阻塞goroutine,直到从goroutine中收发到数据为止
- 当存在可以收发的channel时就执行对应的case,否则就执行default
break和continue
go中的break有一项功能,就是可以跳到指定标签的循环,例如:
OuterLoop://我这里给最外层循环打上了OuterLoop的标签
for i := 0; i < 2; i++ {
for j := 0; j < 5; j++ {
switch j {
case 2:
fmt.Println(i, j)
break OuterLoop//这里就不是跳出内层循环了,而是直接跳出最外层循环
case 3:
fmt.Println(i, j)
break OuterLoop
}
}
}
continue同理,跳到指定标签循环的下一次循环
函数
func function_name( [parameter list] ) [return_types] {
函数体
}
函数可以返回多值
- 未定义长度的数组只能传给不限制数组长度的函数,定义了长度的数组只能传给限制了相同数组长度的函数
匿名函数
- 匿名函数就是没有定义函数名的函数,可以传给函数变量
闭包(closure)
- 闭包函数是高阶函数中的内部函数,其需要等待高阶函数捕获自由变量之后才能生成,其有点像生成模板一样,先写了些代码逻辑,确定了一部分功能,等到捕获自由变量之后就能生成另一部分功能了
defer(延迟执行语句)
- 延迟调用函数是在 defer 所在函数结束前进行(包括panic之后),return后进行。常使用在释放资源时,比如关闭文件,解锁等等。如果有多个defer,defer会串成一个链表,依次逆序调用(写在最后面的最先被执行),相当于一个栈。==defer链表只与当前goroutine相关联==
- defer的函数传参是立马计算,并不是在当前函数退出之前计算
- recover只能通过defer发生作用
- panic只会触发当前goroutine的defer函数
接口型函数
// A Getter loads data for a key. type Getter interface { Get(key string) ([]byte, error) } // A GetterFunc implements Getter with a function. type GetterFunc func(key string) ([]byte, error) // Get implements Getter interface function func (f GetterFunc) Get(key string) ([]byte, error) { return f(key) }
==对于切片,map,channel的拷贝都是浅拷贝(只拷贝了引用,底层数据未拷贝)==
- 函数传参和返回都会发生拷贝
数组和切片
==切片相当于一个窗口,是对底层数组的引用==
切片就是动态数组,可以动态扩展容量,无需指定大小,它有三个元素:
一个指针指向切片的开始位置
Len,切片的实际长度
cap,底层数组的最大长度(只能向后看)
切片如果改变元素是会对所有引用及原数组改变的,因为他实际是一个指针
数组初始化方法,例: arr := [3]int{3,4,5}(==数组大小必须固定==),[…]type可以根据初始化的个数来判断大小
切片初始化方法,例:arr := []int{3,4,5}(没指定大小)
数组中取元素给切片(或切片元素给其他切片)
比如有一个数组a,他是[n]int型数组
a[x:y]表示:从a[x]取起到a[y-1],x为开始索引,y为结束索引(取到y-1)
不填x和y,默认第一个为0,第二个为n
- a[:],同等a[0:n],即获取a中所有元素
- a[x:]从a 取起到a[n]
- a[:y]从a[0]开始取其到a[y-1]
- a[0:0]切片清空
创建切片的方法
==创建新切片==
普通方法创建:
创建切片也是通过先创建数组然后再通过指针创建的
var arr []int,切片为nil,无元素arr := []int{1,2,3}有初始化元素make函数创建(初始化切片元素到len的元素为0):
slice1 := make([]type, len,[cap]),省略cap默认等于len,cap就是底层数组的大小
==引用原数组或原切片的一部分==
引用另一个数组的一部分:
s := arr[start:end],即引用原数组或原切片start到end-1的元素
切片中追加元素
切片追加元素用append(切片名,元素),要考虑append会不会超过cap:
1)如果没超过cap,则仍是返回旧切片(引用旧数组)
2)如果超过cap,遵循一定规则增加容量,参考《GO语言设计与实现》P65,==一定会返回新切片(引用新数组)==
tips:(”…“三个点表示任意参数)
使用 slice…表示slice中的所有元素,方便用于append
slice1=append(slice1,slice2...) //slice2中的元素一个个追加入slice1中,这样不用一个个写出来了
切片复制
copy( destSlice, srcSlice),从源切片(可以是部分)拷贝到目标切片,注意此深拷贝不会扩容,如果要深拷贝一个新切片出来,可以使用dest_slice := append([]int{},src_slice...)
切片删除元素
原地append(元素前移法)
a = []int{1, 2, 3}
a = append(a[:0], a[1:]...) // 删除开头1个元素(把第1个截掉,后面元素追加上来)
a = append(a[:0], a[N:]...) // 删除开头N个元素
a = append(a[:i], a[i+1:]...) // 删除中间1个元素(截到中间那个元素前,然后把中间后面的元素追加上来)
a = append(a[:i], a[i+N:]...) // 删除中间N个元素
range和for-each循环
for key, value := range 数组或切片或map {
代码块
}
使用range可以搭配for循环遍历数组、切片、map和字符串等,以key-value的形式返回(数组和切片的key是索引值),如果不需要key或者value可以用__占位符替代。使用range还可以搭配可变参数,e.g:
func myfunc(args ...int) {
for _, arg := range args {
fmt.Println(arg)
}
}
可变参数实际上就是一个切片,并且可以用args...继续传给其他函数
tips:
需要注意的是,value为值的拷贝,所以只具有可读性,对这个value值的改变不会改变原来集合中的值
for range遍历hash的顺序是不定的
字符串
GO中的string是==只读==的,其有一个指向字节数组的指针和数组的大小
如果读写字符串,需要将其转换为[]byte
Tips:
- 如果字符串拼接次数多可以用strings.Builder声明变量,然后调用WriteString()方法,因为字符串拼接是会拷贝字符串的
Map
参考:深度解密Go语言之map - Stefno - 博客园
==注意键的类型要是可Hash的==
创建map
var 变量名 map[key_type]value_type用make函数创建:
变量名 := make(map[key_type]value_type,[cap])
tips:
value_type可以是切片,这样一个key就对应多个value值了,例如:父进程的pid作为key,多个子进程的pid作为切片元素
map中追加元素
直接key-value方法赋值即可
map删除元素
delete(map,key)
map访问
v := map[key]
v,ok := map[key] //ok代表key的值是否存在,更推荐这种
container/list
实现为双向循环链表
list为element+len(链表长度,==不包括哨兵==),element才是具体节点,value是interface{}类型
创建链表
变量 := list.New(),New()返回一个*list,链表无节点,只有哨兵,len为0
链表中插入元素
这里head为*list,代表链表的头
尾部插入:head.PushBack(任意类型元素)
前部插入:head.PushFront(任意类型元素)
PushBack和PushFront都返回一个*Element,用来方便在链表中插入节点
这里用mark表示PushBack或PushFront返回的*Element
在mark后插:head.InsertAfter(任意类型元素,mark)
在mark前插:head.InsertBefore(任意类型元素,mark)
删除链表元素
head.Remove(mark)
遍历链表元素
for i := l.Front(); i != nil; i = i.Next() {
fmt.Println(i.Value)
}
/*
Front()表示获取第一个节点,Back()表是获取最后一个节点,Next()表示下一节点,Value获取节点值
*/
container/Ring和container/heap
Ring也是双向循环链表,但是长度固定
heap可以用来进行堆排序
指针
指针的用法与c语言相同
也可以用 new()函数来创建指针,例:var_name := new(type),这样var_name保存的是type类型变量的首地址
结构体
type 类型名 struct {
字段1 字段1类型
字段2 字段2类型
…
}
tips:
- 结构体中的字段可以内嵌其他结构体,被内嵌的结构体中的字段可以直接引用,而不用多层引用(有点像继承),e.g:
a.b.c.d可以直接用a.d
- go中指针结构体中的字段可以直接引用(用了语法糖),而不用像C中一样用->
结构体实例化方式
以创建指针的方式
ins := new(T)其中T为结构体类型名,返回一个*T
取结构体的地址实例化
ins := &T{}同样返回一个*T,然后
T.字段名赋值,或者指明字段的方式ins := &结构体类型名{ 字段1: 字段1的值, 字段2: 字段2的值, … }字段与字段之间用,分隔,这种方式某个字段可以省略,那么字段值取省略值
或者多值方式
ins := &结构体类型名{ 字段1的值, 字段2的值, … }这种方式省略字段名,但是所有结构体内的字段都必须赋值
直接定义
声明方式也是指明字段和多值方式,只不过变量用的是T而不是*T而已
接口
接口底层实现参考:深度解密Go语言之关于 interface 的10个问题 - Stefno - 博客园
go中的接口是非侵入式的,不同于Java这些语言需要显式的进行implements接口,go类型实现接口不需要进行声明,只需要实现接口中的所有方法,所以类型中的方法是接口中方法的超集。非侵入式的好处还在于,不同于面向对象接口需要根据业务来事先制定接口中的方法,甚至可以先实现类型再声明接口,可扩展性强,而且如果以后想把接口中一些方法独立出来列为新接口,按照Java这些侵入式的方法,是需要重新implements新接口并且重新编译的。而且,类型实现接口甚至不需要引入包
type 接口类型名 interface{
方法名1( 参数列表1 ) 返回值列表1
方法名2( 参数列表2 ) 返回值列表2
…
}
参数名和返回值名都可以省略
实现接口
e.g:
// 定义一个数据写入器
type DataWriter interface {
WriteData(data interface{}) error
}
// 定义文件结构,用于实现DataWriter
type file struct {
}
// 实现DataWriter接口的WriteData方法
// 这里方法要指定接收者
func (d *file) WriteData(data interface{}) error {
// 模拟写入数据
fmt.Println("WriteData:", data)
return nil
}
==注意接受者如果不是指针类型而是普通类型的话,在方法内修改实例的属性不会改变原实例的值,因为是拷贝,而指针指向了原实例==
tips:
- 只有当实现了接口的类型赋值给接口变量时,编译器才会去比较这个类型中是否全部实现了接口中的方法
- 内嵌结构体也能实现接口,这样外层结构体就不必再实现一次了,避免了冗余代码
- 实现类型不能是系统内置类型,只能是结构体或者是用type定义的新类型
- 接口中可以像结构体一样嵌套接口,这样接口中就拥有被嵌套接口的所有方法了
- 注意接口可能存在动态类型而值是nil,它本身并不与nil相等,它是存在动态类型的
error接口
type error interface {
Error() string
}
如果要自定义error可以实现Error()方法,返回错误信息,打印error默认调用的是error.Error()
errors包中的errors.New(“错误信息”)就是返回一个error对象
eface和iface
eface是interface{}的底层结构体,不包含任何方法,只有指向数据的指针和指向具体类型的指针
//iface:
type iface struct{
tab *itab //itab中不仅包括接口的类型,还包括指向具体类型的指针,还有方法
data unsafe.Pointer //指向数据的指针
}
宕机(panic)和宕机恢复(recover)
Go语言没有异常系统,其使用 panic 触发宕机类似于其他语言的抛出异常(打印堆栈和信息),recover 的宕机恢复机制就对应其他语言中的 try/catch 机制。
panic()和recover()都为内置函数,panic接收一个interface{}类型参数
如果当前的 goroutine 陷入panic,调用 recover 可以捕获到 panic 的输入值,并且恢复正常的执行。
recover只能与defer搭配使用,用于恢复,相当于Java中的catch,try中发生错误,直接将控制交给catch
e.g:
web服务器崩溃时用recover关闭连接,或者向客户端传递异常信息用于调试
Sort包
排序
如果要对切片元素进行自定义排序,需要实现sort.Interface接口中的三个方法:
- Len() int // 获取元素数量
- Less(i, j int) bool // i,j是序列元素的指数。即表示怎么样算一个元素小于另一个元素,由自己实现
- Swap(i, j int) // 交换元素
==注意,系统内置变量是不能够用来实现接口的,必须用type声明新类型==
sort包中内置了一些切片,这些切片已经实现了Interface中的方法,所以直接用这些切片定义,并用sort.Sort方法即可排序

如果是针对于结构体想进行排序就要针对于某个字段写Less方法了
这里推荐sort包中更快的实现方式,==sort.Slice方法==,这样就不必实现sort.Interface中所有方法,直接提供一个切片和回调函数就行了(就是提供一个Less()函数,怎么比较切片中元素的大小)
func Slice(slice interface{}, less func(i, j int) bool)
查找
sort.Search(n int, f func(i int) bool) int
利用二分查找返回f(i)==true时最小的索引值,f是用户提供的回调函数,当[0,i)时f为false,>=i时f为true,通常是搜索array或者slice时使用,n传入len(arrry或者slice)
goroutine(核心)
参考资料:go语言之行–golang核武器goroutine调度原理、channel详解 - W-D - 博客园
goroutine就是由go语言实现的用户级别线程,goroutine通过通道来相互传递消息
使用方法:
go 函数名(实参)即可运行一个goroutine
GMP模型
协程就是用户态线程,比内核态线程更加轻量,拥有自己的栈空间,程的切换由用户控制,切换开销小,线程的切换由操作系统控制,切换开销相对来说较大

- M:M代表操作系统级别的线程,由操作系统调度器管理,一个M对应一个P
- G:代表一个goroutine,表示待执行的任务,相当于==用户级别线程(协程)==,切换开销小,新创建的G会先保存在P的本地队列(256长度的数组),如果本地队列存不下则会放到全局队列当中
- P:P全称是Processor,处理器,它的主要用途就是用来将M和G关联起来,所以它也维护了一个自己的local goroutine队列,里面存储了所有需要它来执行的goroutine。当然还存在一个全局的global goroutine队列,如果local队列中的goroutine运行完了也会取global队列中的goroutine来运行。P在go程序运行时就会创建,根据GOMAXPROCS来确定数量,默认是系统逻辑核数量
- Sched:用户态级别调度器,负责将goroutine调度到具体某个队列中(可以是新的goroutine加入,或者是从其他队列中取得的goroutine(work stealing机制))
==GMP模型相对于GM模型有了P的本地队列,对于全局队列的锁竞争减少,有了work-stealing机制,有了对于M被goroutine系统调用阻塞的切换机制==
如果直接在M上实现本地队列,一旦M被G阻塞,则M上的其他G也会被阻塞,而且M的数量会不断地增加
GMP流程
调用 go func()创建一个goroutine;
新创建的G优先保存在P的本地队列中,如果P的本地队列已经满了就会保存在全局的队列中;
M需要在P的本地队列弹出一个可执行的G,如果P的本地队列为空,则先会去全局队列中获取G,如果全局队列也为空则去其他P的本地队列中偷取G放到自己的队列当中(work-stealing)
G将相关参数传输给M,为M执行G做准备
当M执行某一个G时候如果发生了系统调用产生导致M会阻塞,如果当前P队列中有一些G,runtime会将线程M和P分离,然后再获取空闲的线程或创建一个新的内核级的线程来服务于这个P,阻塞调用完成后G被销毁将值返回;
销毁G,将执行结果返回
当M系统调用结束时候,这个M会尝试获取一个空闲的P执行,如果获取不到P,那么这个线程M变成休眠状态, 加入到空闲线程中。
channel通道
==channel本质上是一种有锁队列==,所以是并发安全的。发送和接收都遵循FIFO,发送使用ch <- 元素,接收使用<- ch
无缓冲管道(同步):
ch := make(chan 类型)
发送方向通道发送数据后,若没有接收方取数据就会阻塞,直到接收方接收为止;接收方同理
有缓冲管道(异步):
ch := make(chan 类型,缓冲区大小)
不同于无缓冲的情况,发送方可以不用阻塞地一直向管道发送数据,直到缓冲区满之后才会阻塞(进入发送等待队列);接收方也可以不用阻塞地从通道中取数据(当然是缓冲区中有数据的情况),直到没有数据可取为止,则接收方阻塞(进入接收等待队列)
空结构体通道
因为空结构体struct{}不占内存,所以可以用来作为信号来同步,当一个goroutine完成时,可以通过发送struct{}{}表示已完成,通知另一端的goroutine
单向通道
可以用在返回类型里,限定函数调用方的行为,双向通道赋值给单向通道可以自动转换
- 只能发不能接类型:
chan<- - 只能接不能发类型:
<-chan,比如可以先定义一个双向通道往里面塞数据,然后返回单向通道,这种通道只能从里面读数据
- 只能发不能接类型:
关闭通道
使用原语close(chan)关闭通道,读取关闭的通道会读取到相应类型的零值,如果继续向已关闭的channel发送数据会触发panic
go func(in <-chan int) { // Using for-range to exit goroutine // range has the ability to detect the close/end of a channel for x := range in { fmt.Printf("Process %d\n", x) } }(in) //range可以用来遍历通道,通道如果关闭了range会自动结束
tips
- 注意发送到通道中的数据也经过了拷贝
_,ok:=<-chan从通道中读取数据的第二个boolean值可以判断通道是否已关闭
Sync包
sync.WaitGroup
有时候主线程需要等待其他goroutine执行完毕,用time.Sleep的方法不太好,无法估计所有goroutine完成的时间,所以用sync.WaitGroup结构体来做同步比较好
方法:
Add(delta int)
delta表示要执行的goroutine数量,WaitGroup中的计数器+1
Done()
sync.WaitGroup变量调用一次Done(),结构体中的计数器(delta数)就-1(实际上是向Add方法传入了负数)
Wait()
一直阻塞,直到计数器变为0为止,可以放在main函数的最后,等待所有其他goroutine done,然后结束程序
互斥锁和读写互斥锁
互斥锁
sync.Mutex,对等操作系统里学的mutex
- 可以使用defer mu.Unlock()避免忘记解锁
- 避免重复锁定或解锁
- 当前goroutine如果不能获取到锁(被其他goroutine持有),则可能会进入自旋状态(进入自旋状态的条件比较苛刻)
- 如果goroutine对锁的等待时间超过1ms,互斥锁会从正常模式进入饥饿模式
读写互斥锁
sync.RWMutex,封装了Mutex,还内置读者计数器,可用于单写者多读者,效率比普通互斥锁要高
- 可以多次调用读锁
sync.Once
sync.Once.Do接收一个无参函数,只执行一次该函数,该结构体有个字段done表示是否已执行过该函数
sync.Cond
sync.Cond需要传入一个锁来发生作用,作用在于,可以避免goroutine长时间由于for循环监听变量状态变化而占据资源,当状态不满足时可以先进行等待(形成goroutine等待链),等待其他goroutine唤醒
Wait()休眠并等待被唤醒,加入goroutine等待链中
Signal()唤醒等待链最前面的goroutine
Broadcast()唤醒等待链中所有的goroutine
sync/atomic包
原子操作即是进行过程中不能被中断的操作,针对某个值的原子操作在被进行的过程中,CPU绝不会再去进行其他的针对该值的操作。为了实现这样的严谨性,原子操作仅会由一个独立的CPU指令代表和完成。原子操作是无锁的,常常直接通过CPU指令直接实现。 事实上,其它同步技术的实现常常依赖于原子操作。
即使代码在加了锁的临界区中运行也有可能会被系统中断,比如发生上下文切换,所以需要原子操作防止被中断。==也可以用来保护共享变量,如基本类型==
原子操作有:
加法(add)
比较并交换(compare and swap,简称 CAS)
CAS可以进行无锁编程,做到在没有变量被阻塞的情况下实现变量的同步,所以也叫非阻塞同步
CAS有点像乐观锁,将期望old值与当前值比较,如果相同就赋new值,并且返回true;否则不赋值,并且返回false
乐观锁适用于==多读==场景,总是认为别人没有修改数据
加载(load)
存储(store)
交换(swap)
sync.Map
并发安全map,适用于读多写少的场景,其涵盖两个字典,一个是atomic.Value的只读字典,一个是普通脏字典。读时无需调用锁,但写时需要锁。
反射
主要函数:
func TypeOf ( i interface{} ) Type
func ValueOf ( i interface{} ) Value
func DeepEqual(x, y interface{}) bool
- Type 是一个接口,定义了很多相关方法,用于获取类型信息。(返回的实际上是rtype,rtype与_type基本一致,实现了Type接口)
- Value是一个结构体,既保存了类型信息也保存了类型值(类似eface),里面保存了rtype也保存了指向实体的指针
- Type,Value,interface之间可以相互转换
- DeepEqual用于比较两个变量是否“深度”相等,可以用于比较复杂的类型,简单的类型当然自己实现肯定是效率更高的(比如结构体之间比较要如何算相等),反射比较费时,但是比较复杂的可以通过DeepEqual进行比较。两个interface是可以用DeepEqual来进行对比的,即比较两者的实体是否相等
Context
参考:深度解密Go语言之context - Stefno - 博客园
通常Http server每来一个请求都会启动多个goroutine来服务这个请求,有的goroutine去下游获取数据,有的goroutine去数据库拿数据,形成多个goroutine组成的树。如果有的下游服务响应速度较慢,而又没有超时控制机制,会导致等待的goroutine越来越多。可以通过context设置超时时间,超过超时时间,所有goroutine快速退出,回收资源。
context用于goroutine组成的树中==同步取消信号==以减少资源消耗,==或者传递请求ID和用户认证token==
常用方法
这些方法通常第一个参数传入一个父context,会返回一个子context和cancel函数,如果提前调用cancel函数,WithTimeout会关掉定时器
WithCancel(parant Context)
WithTimeout(parent Context,timeout time.Duration)
WithDeadline(parent Context,d time.Time)
- Tips:
- 如果Context已经被取消,可以从当前context的Done()方法中读取出相应的零值,表示channel已经被关闭
- 如果父Context被取消,是递归取消的,子Context的done通道都会被关闭,都可从Done()方法中读取出相应的零值
内存分配
引用:https://zhuanlan.zhihu.com/p/59125443
GO内存分配采用TCMalloc的机制,使用多级缓存:线程缓存,中心缓存和页堆,并根据对象的大小采取不同的内存分配策略。每个线程都会分配一个线程缓存(runtime.mcache)进行微小对象的分配,线程缓存持有一定数量的不同种类的runtime.mspan(==内存管理单元==),mspan负责一定数量内存页的分配和回收,mspan会根据跨度类来决定所能存储的对象大小和数量(决定特定大小的对象的分配),内存分配时,先确定分配对象的大小和跨度类,然后根据跨度类确定mspan,然后由mspan来找是否有空闲的对象可供分配
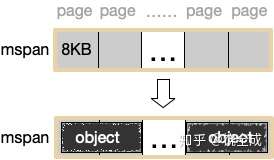
每个线程持有线程缓存可以避免锁竞争单来的内存分配性能影响。当线程缓存不能满足小对象的分配时,会去中心缓存补充runtime.mspan,每个mcentral保存一种mspan列表,当中心缓存也无法满足对象的分配时,会去页堆申请mspan用于切割成小对象。大对象由页堆直接分配。
大体上的分配流程:
- 32KB 的对象,直接从mheap上分配;
- <=16B 的对象使用mcache的tiny分配器分配;
- (16B,32KB] 的对象,首先计算对象的规格大小,然后使用mcache中相应规格大小的mspan分配;
- 如果mcache没有相应规格大小的mspan,则向mcentral申请
- 如果mcentral没有相应规格大小的mspan,则向mheap申请
- 如果mheap中也没有合适大小的mspan,则向操作系统申请
垃圾收集
三色标记法(基础,用于标记和清除对象),并发回收(尽可能减小暂停程序带来的性能影响),混合写屏障(避免因并发改动指针而引发的错误的垃圾回收)
触发时机
- 用户通过runtime.GC()函数手动触发
- 后台定时检查,超过一定时间仍没有触发则会触发,默认设置2分钟
- 堆内存到达一定比例时触发,默认是上次垃圾回收时堆内存大小的2倍
- 线程缓存中内存管理单元不足时,申请分配大对象时
Last modified on 2021-03-07